. © 2017 Qun Zheng and Yuan-Hang Zhang")
ES³: Evolving Self-Supervised Learning of Robust Audio-Visual Speech Representations
Published in The IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
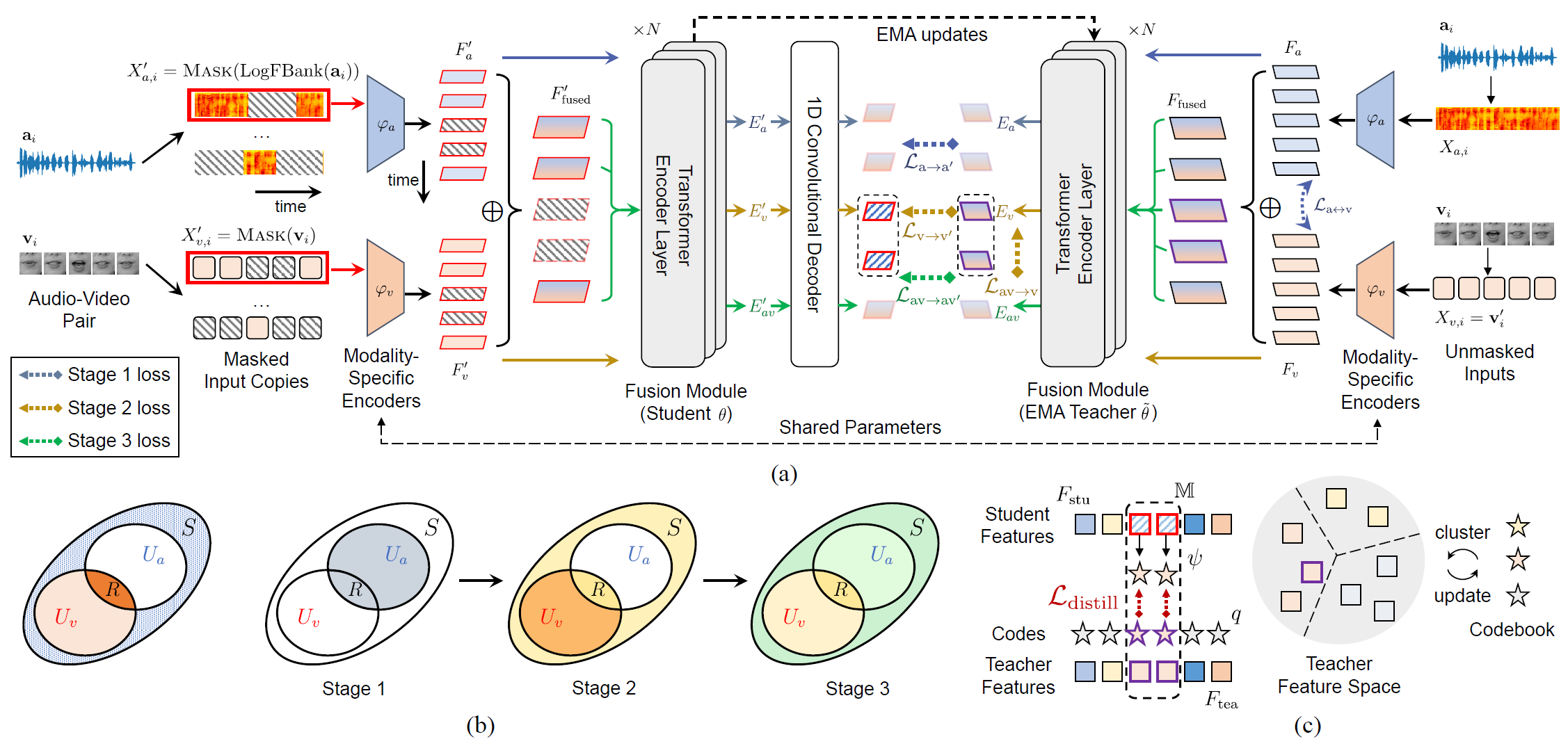
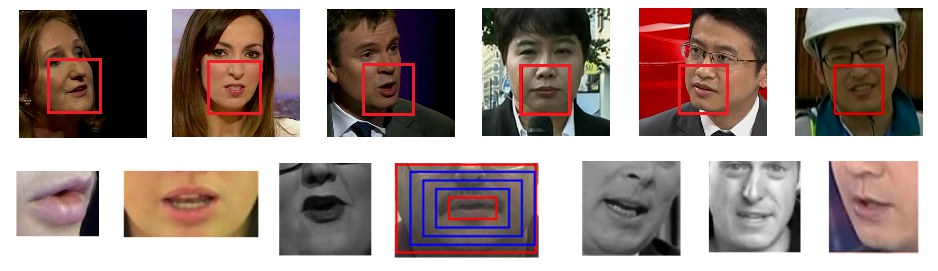
Over the past few years, the task of audio-visual speech representation learning has received increasing attention due to its potential to support applications such as lip reading, audio-visual speech recognition (AVSR), and speech enhancement etc. Recent approaches for this task (e.g. AV-HuBERT) rely on guiding the learning process using the audio modality alone to capture information shared between audio and video. In this paper, we propose a novel strategy, ES³ for self-supervised learning of robust audio-visual speech representations. We reframe the problem as the acquisition of shared, unique (modality-specific) and synergistic speech information to address the inherent asymmetry between the modalities, and adopt an evolving approach to progressively build robust uni-modal and joint audio-visual speech representations. Specifically, we first leverage the more easily learnable audio modality to capture audio-unique and shared speech information. On top of this, we incorporate video-unique speech information and bootstrap the audio-visual speech representations. Finally, we maximize the total audio-visual speech information, including synergistic information. We implement ES³ as a simple Siamese framework and experiments on both English benchmarks (LRS2-BBC & LRS3-TED) and a newly contributed large-scale sentence-level Mandarin dataset, CAS-VSR-S101 show its effectiveness. In particular, on LRS2-BBC, our smallest model is on par with SoTA self-supervised models with only 1/2 parameters and 1/8 unlabeled data (223h).
Recommended citation: Yuanhang Zhang, Shuang Yang, Shiguang Shan and Xilin Chen. ES³: Evolving Self-Supervised Learning of Robust Audio-Visual Speech Representations. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 17-21, 2024, Seattle, Washington, USA. https://cvpr.thecvf.com/virtual/2024/poster/31590