. © 2017 Qun Zheng and Yuan-Hang Zhang")
ES³: Evolving Self-Supervised Learning of Robust Audio-Visual Speech Representations
Published in The IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
Recommended citation: Yuanhang Zhang, Shuang Yang, Shiguang Shan and Xilin Chen. ES³: Evolving Self-Supervised Learning of Robust Audio-Visual Speech Representations. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 17-21, 2024, Seattle, Washington, USA. https://cvpr.thecvf.com/virtual/2024/poster/31590
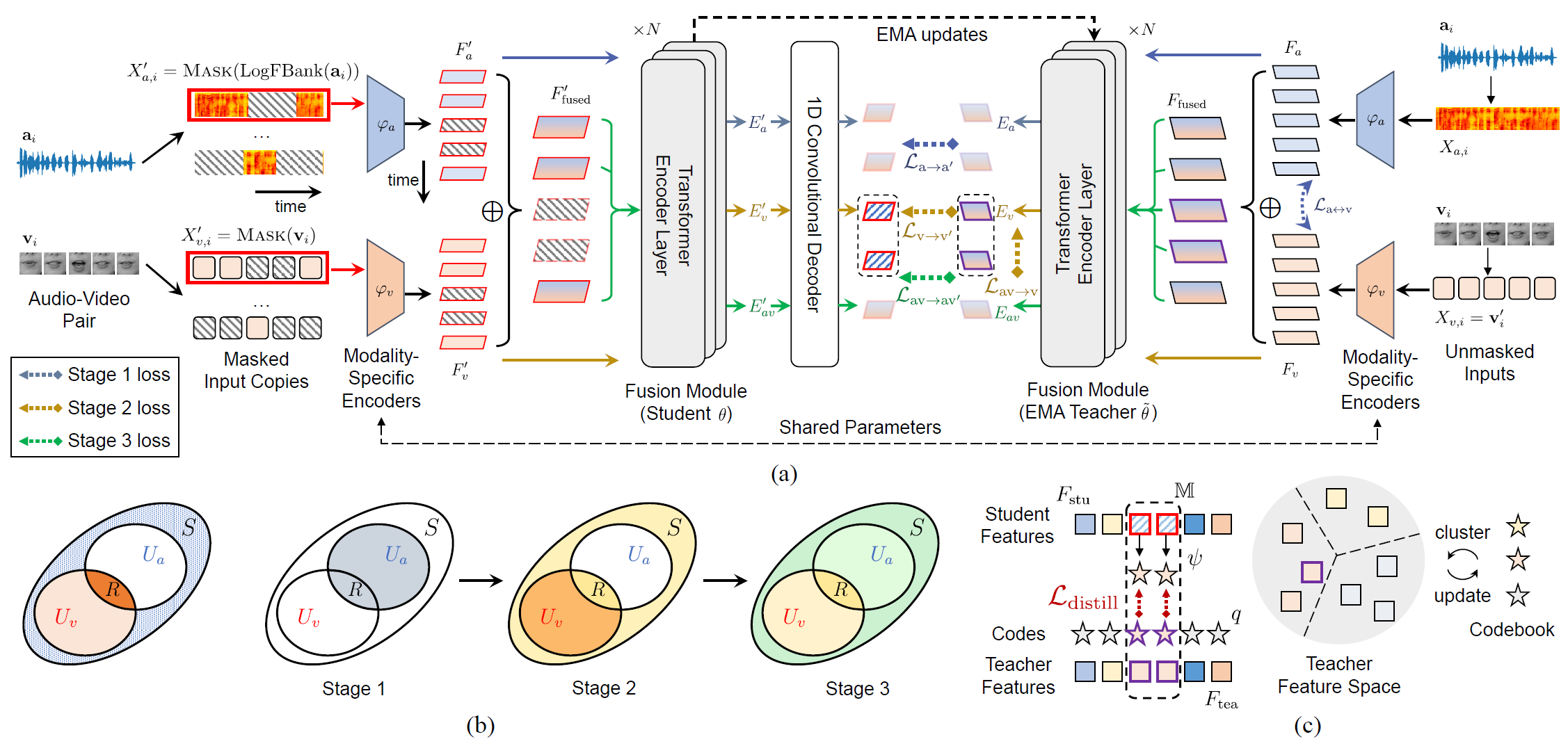

Abstract: We propose a novel strategy, ES³, for self-supervised learning of robust audio-visual speech representations from unlabeled talking face videos. While many recent approaches for this task primarily rely on guiding the learning process using the audio modality alone to capture information shared between audio and video, we reframe the problem as the acquisition of shared, unique (modality-specific) and synergistic speech information to address the inherent asymmetry between the modalities. Based on this formulation, we propose a novel “evolving” strategy that progressively builds joint audio-visual speech representations that are strong for both uni-modal (audio & visual) and bi-modal (audio-visual) speech. First, we leverage the more easily learnable audio modality to initialize audio and visual representations by capturing audio-unique and shared speech information. Next, we incorporate video-unique speech information and bootstrap the audio-visual representations on top of the previously acquired shared knowledge. Finally, we maximize the total audio-visual speech information, including synergistic information to obtain robust and comprehensive representations. We implement ES³ as a simple Siamese framework and experiments on both English benchmarks and a newly contributed large-scale Mandarin dataset show its effectiveness. In particular, on LRS2-BBC, our smallest model is on par with SoTA models with only 1/2 parameters and 1/8 unlabeled data (223h).