Mathematical Analysis
Material from my first and second year calculus courses.
. © 2017 Qun Zheng and Yuan-Hang Zhang")
Material from my first and second year calculus courses.
Final project for Prof. Ann Ross’s Media Literacy class in Spring 2017.
Published:
In this paper reading session, we review important work on audio-based and audio-visual speech recognition, along with a line of work in multi-modal learning.
Translation of book by John Hopcroft, Avrim Blum and Ravi Kannan.
Mirrors for some large-scale datasets.
Published in IEEE F&G, 2019

We present a naturally-distributed large-scale benchmark for lip reading in the wild, named LRW-1000, which contains 1000 classes with about 745,187 samples from more than 2000 individual speakers. To the best of our knowledge, it is the largest word-level lipreading dataset and also the only public large-scale Mandarin lipreading dataset.
Recommended citation: Yang, S., Zhang, Y., Feng, D., Yang, M., Wang, C., Xiao, J., Long, K., Shan, S. and Chen, X., 2019. LRW-1000: A Naturally-Distributed Large-Scale Benchmark for Lip Reading in the Wild. International Conference on Automatic Face and Gesture Recognition, 2019 (Oral). https://arxiv.org/pdf/1810.06990.pdf
Published in IEEE F&G, 2020
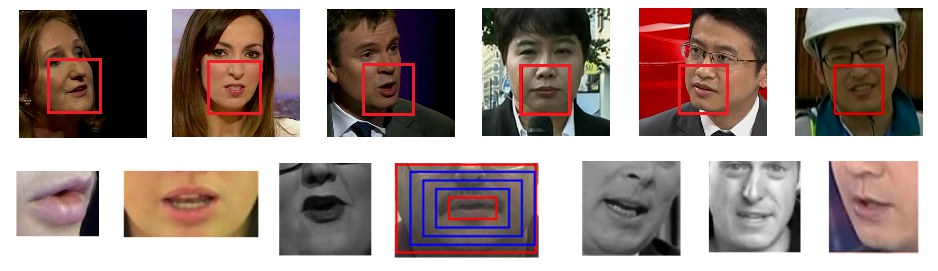
We revisit a fundamental yet somehow overlooked problem in visual speech recognition: can VSR models benefit from reading speech in extraoral facial regions, i.e. beyond the lips? We find by experimenting on three benchmarks, that incorporating information from extraoral facial regions is always beneficial, even using only the upper face. We also introduce a simple yet effective method based on Cutout to learn more discriminative features for face-based VSR, which show clear improvements over existing state-of-the-art methods that use the lip region as inputs.
Recommended citation: Zhang, Y., Yang, S., Xiao, J., Shan, S. and Chen, X., 2020. Can We Read Speech Beyond the Lips? Rethinking RoI Selection for Deep Visual Speech Recognition. International Conference on Automatic Face and Gesture Recognition, 2020 (oral). https://arxiv.org/pdf/2003.03206.pdf
Published in ACM Multimedia, 2021

We propose a new efficient framework, the Unified Context Network (UniCon), for robust active speaker detection (ASD). Traditional methods for ASD usually operate on each candidate’s pre-cropped face track separately and do not sufficiently consider relationships among the candidates. This potentially limits performance, especially in challenging scenarios with low-resolution faces, multiple candidates, etc. Our solution is a novel, unified framework that focuses on jointly modeling multiple types of contextual information: spatial context to indicate the position and scale of each candidate’s face, relational context to capture the visual relationships among the candidates and contrast audio-visual affinities with each other, and temporal context to aggregate long-term information and smooth out local uncertainties. Based on such information, our model optimizes all candidates in a unified process for robust and reliable ASD. A thorough ablation study is performed on several challenging ASD benchmarks under different settings. In particular, our method outperforms the state-of-the-art by a large margin of about 15% mean Average Precision (mAP) absolute on two challenging subsets: one with three candidate speakers, and the other with faces smaller than 64 pixels. Together, our UniCon achieves 92.0% mAP on the AVA-ActiveSpeaker validation set, surpassing 90% for the first time on this challenging dataset at the time of submission.
Recommended citation: Zhang, Y., Yang, S., Liang, S., Liu, X., Wu, Z., Shan, S. and Chen, X., 2021. UniCon: Unified Context Network for Robust Active Speaker Detection. 29th ACM International Conference on Multimedia (ACM Multimedia 2021), Chengdu, China, October 20-24, 2021 (oral). https://arxiv.org/pdf/2108.02607
Published in The IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
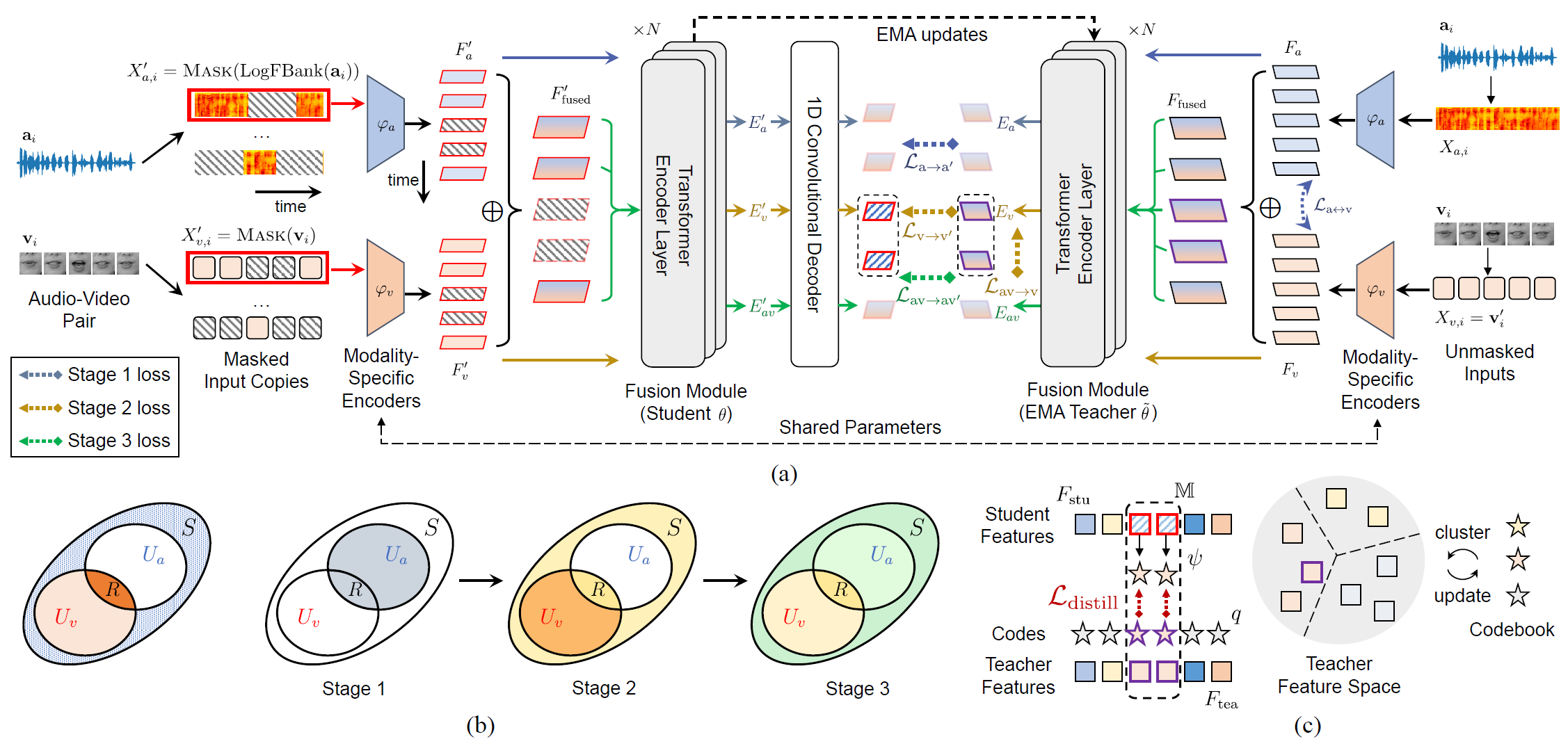
Over the past few years, the task of audio-visual speech representation learning has received increasing attention due to its potential to support applications such as lip reading, audio-visual speech recognition (AVSR), and speech enhancement etc. Recent approaches for this task (e.g. AV-HuBERT) rely on guiding the learning process using the audio modality alone to capture information shared between audio and video. In this paper, we propose a novel strategy, ES³ for self-supervised learning of robust audio-visual speech representations. We reframe the problem as the acquisition of shared, unique (modality-specific) and synergistic speech information to address the inherent asymmetry between the modalities, and adopt an evolving approach to progressively build robust uni-modal and joint audio-visual speech representations. Specifically, we first leverage the more easily learnable audio modality to capture audio-unique and shared speech information. On top of this, we incorporate video-unique speech information and bootstrap the audio-visual speech representations. Finally, we maximize the total audio-visual speech information, including synergistic information. We implement ES³ as a simple Siamese framework and experiments on both English benchmarks (LRS2-BBC & LRS3-TED) and a newly contributed large-scale sentence-level Mandarin dataset, CAS-VSR-S101 show its effectiveness. In particular, on LRS2-BBC, our smallest model is on par with SoTA self-supervised models with only 1/2 parameters and 1/8 unlabeled data (223h).
Recommended citation: Yuanhang Zhang, Shuang Yang, Shiguang Shan and Xilin Chen. ES³: Evolving Self-Supervised Learning of Robust Audio-Visual Speech Representations. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 17-21, 2024, Seattle, Washington, USA. https://cvpr.thecvf.com/virtual/2024/poster/31590
List of projects I am currently working on or have finished.
This is a somewhat comprehensive list of all materials I am currently translating.